the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 03 Jun 2020
| 03 Jun 2020
Development of pedotransfer functions for water retention in tropical mountain soil landscapes: spotlight on parameter tuning in machine learning
Anika Gebauer
Monja Ellinger
Victor M. Brito Gomez
Mareike Ließ
Machine-learning algorithms are good at computing non-linear problems and fitting complex composite functions, which makes them an adequate tool for addressing multiple environmental research questions. One important application is the development of pedotransfer functions (PTFs). This study aims to develop water retention PTFs for two remote tropical mountain regions with rather different soil landscapes: (1) those dominated by peat soils and soils under volcanic influence with high organic matter contents and (2) those dominated by tropical mineral soils. Two tuning procedures were compared to fit boosted regression tree models: (1) tuning with grid search, which is the standard approach in pedometrics; and (2) tuning with differential evolution optimization. A nested cross-validation approach was applied to generate robust models. The area-specific PTFs developed outperform other more general PTFs. Furthermore, the first PTF for typical soils of Páramo landscapes (Ecuador), i.e., organic soils under volcanic influence, is presented. Overall, the results confirmed the differential evolution algorithm's high potential for tuning machine-learning models. While models based on tuning with grid search roughly predicted the response variables' mean for both areas, models applying the differential evolution algorithm for parameter tuning explained up to 25 times more of the response variables' variance.
- Article
(3933 KB) - Full-text XML
- BibTeX
- EndNote




Machine-learning algorithms are good at fitting highly complex non-linear functions (Witten et al., 2011). Major application fields in soil science investigate the soils' spatial variability (Heung et al., 2016), relate data from soil sensing to soil properties (Viscarra Rossel et al., 2016), or develop pedotransfer functions (PTFs; Botula et al., 2014; Van Looy et al., 2017). McBratney et al. (2019) give a time line on developments in pedometrics, which refers to machine learning in multiple applications.
Pedotransfer functions derive laborious and complex soil parameters (response variables) from more readily available soil properties (predictor variables). Most PTFs are developed to predict soil hydraulic properties. Reviews on the methodologies involved are provided by Pachepsky and Rawls (2004), Shein and Arkhangel'skaya (2006), and Vereecken et al. (2010). Machine-learning algorithms applied for PTF development include support vector machines (Lamorski et al., 2008) artificial neural networks (Haghverdi et al., 2012), and regression trees (Tóth et al., 2015).
According to Van Looy et al. (2017), most PTFs are developed for mineral soils, while PTFs applicable to organic soils or soils with specific properties like volcanic ash soils are highly underrepresented. Patil and Singh (2016) and Botula et al. (2014) provide reviews of hydrological PTFs for mineral soils of certain tropical and temperate regions. With particle size distribution (PSD) being the basic input parameter to derive soil hydrologic properties, most PTFs also use the bulk density (BD) and soil organic carbon content (SOC) as predictors.
As summarized by Patil and Singh (2016), the application of existing hydrological PTFs is often restricted due to two reasons. Firstly, the majority of PTFs are developed on soils that developed under certain conditions. Often these PTFs cannot be applied in other regions, as the site-specific soil-forming conditions can cause considerable differences in physical and chemical soil properties. This is demonstrated by studies such as Botula et al. (2012) and Moreira et al. (2004), who were able to show that, when applied to independent tropical soil data, existing temperate PTFs perform worse than existing tropical PTFs. Secondly, the applicability of existing PTFs is further restricted by the input data required. As stated by Morris et al. (2019), hydraulic PTFs developed on mineral soils are often inapplicable to organic soils. The measurement of the predictor variable PSD may be hampered by high organic matter contents, and organic soils may not include sufficient mineral soil material to justify PSD analysis at all.
Overall, only a small number of PTFs have been developed for organic soils, and most of them are based on data from specific temperate regions and rely on very specific predictor variables. Korus et al. (2007), for example, related the water retention of Polish peat soils to the ash content, specific surface area, BD, pH, and iron content. In Finish peat soils semiempirical water retention PTFs were developed on different predictors including BD, sampling depth, and botanical residues (Weiss et al., 1998). Although it was never intended to be used for predictions, Rocha Campos et al. (2011) provide the only regression model known to us, which relates the soil hydrologic parameters of tropical organic soils to independent variables (fiber content, mineral material, BD, and organic matter fractions).
The application of machine-learning algorithms requires them to be adjusted to the specific modeling problem using parameter tuning. Tuning parameter values cannot be calculated analytically; thus, in soil science applications grid search is often used as a standard technique (e.g., Babangida et al., 2016; Khlosi et al., 2016; Twarakavi et al., 2009). Grid search works by testing a number of predefined parameter values or combinations of parameter values to finally choose the best. Accordingly, the predominant part of the multivariate parameter space cannot be searched in the case of continuous parameters, and the optimum might not be found. To overcome this limitation, mathematical optimization is a promising alternative.
Commonly applied optimization algorithms include artificial bee colony, simulated annealing, particle swarm optimization, the Nelder–Mead method, Bayesian optimization, or evolutionary and genetic strategies. Their applications range from pattern recognition (e.g., Jayanth et al., 2015; Liu and Huang, 1998), through solving combinatorial problems (e.g., Wang et al., 2003; Reeves, 1993) to parameter tuning in machine learning (e.g., Imbault and Lebart, 2004; Ozaki et al., 2017). We would like to particularly emphasize the differential evolution algorithm. Price et al. (2005), who compared it to various other optimization algorithms, were able to show that it usually leads to better results and comparatively low computing times. This has been confirmed by the results of Chen et al. (2017), who compared differential evolution to particle swarm optimization and a genetic algorithm in landslide modeling, and Yin et al. (2018), who compared differential evolution to simulated annealing, particle swarm optimization, artificial bee colony, and genetic algorithms in geotechnical engineering. It is also able to outperform Bayesian approaches in certain applications. Comparisons of both algorithms led to contradictory results: while some studies found Bayesian approaches to be superior (e.g., Carr et al., 2016), others reported the opposite result (e.g., Schmidt et al., 2019).
The differential evolution algorithm was applied to diverse optimization problems including the prediction of stable metallic clusters (Yang et al., 2018), the navigation of robots (Martinez-Soltero and Hernandez-Barragan, 2018), the classification of microRNA targets (Bhadra et al., 2012), parity-P problems (Slowik and Bialko, 2008), or the parameter tuning of machine-learning models trained to carry out functions such as predicting landslides (Tien Bui et al., 2017). In soil-related research questions it has been applied to optimize parameters of geostatistical models (Brus et al., 2016; Wadoux et al., 2018) and to optimize parameters defining the shape of well-known soil water retention curves (Maggi, 2017; Ou, 2015) among other applications. However, in pedometrics, applications for parameter tuning in machine learning are scarce (e.g., Gebauer et al., 2019).
This study first aims to develop water retention PTFs for two tropical soil landscapes dominated by (1) peat soils and soils under volcanic influence with high organic matter contents, such as those that commonly occur in the Páramo regions (Ecuador), and (2) tropical soils of a dry climate. Currently, PTFs suitable for the soils of these regions are lacking, if any exist at all. The parameter-tuning technique is assumed to affect the performance of the machine-learning-based PTFs. This is why our second and equally important aim is to compare the differential evolution algorithm to grid search. On average, different machine-learning algorithms perform equally well (Wolpert, 2001). We have chosen to fit boosted regression tree models, because we assume that the preeminence of optimization for parameter tuning in machine learning will particularly show when applying it to a machine-learning algorithm that requires not only the fitting of discrete-valued parameters but also the fitting of numerous continuous parameters.
2.1 Research areas
The two soil landscapes investigated are situated in southern Ecuador (Fig. 1). The Quinuas catchment encompasses an area of about 93 km2, including parts of the Cajas National Park (Fig. 1c), and is located between 3000 and 4400 m a.s.l. with a mean annual temperature of between 5.3 and 8.7 ∘C and no seasonality (Carrillo-Rojas et al., 2016). With one peak in the period from March to May and one in October (Celleri et al., 2007), the mean annual precipitation varies between 900 and 1600 mm (Crespo et al., 2011). Due to volcanic ash deposits and the cold and wet climate, soils with a low bulk density and high SOC contents are typical (Buytaert et al., 2007). The Quinuas catchment can be allocated to the Páramo ecosystem (Guio Blanco et al., 2018), which plays a major role in the water supply of the inter-Andean region (Buytaert et al., 2006a, b, 2007).
The Laipuna dry forest region is part of the “Laipuna Conservation and Development Area” and covers approximately 16 km2 (Fig. 1d). Its temperature profile shows little seasonal variability, although there is a wet period from January to May. Depending on the altitude, which ranges between 400 and 1500 m a.s.l., the mean annual temperature varies between 16 and 23 ∘C, and the mean annual precipitation varies between 540 and 630 mm (Peters and Richter, 2011a, b). Additionally, the El Niño–Southern Oscillation influences the area (Bendix et al., 2003, 2011). Laipuna is part of an ecosystem with high biodiversity and many endemic species (Best and Kessler, 1995; Linares-Palomino et al., 2009), which are strongly adapted to the ecosystem and may be threatened by possible climate-induced changes in the water supply.
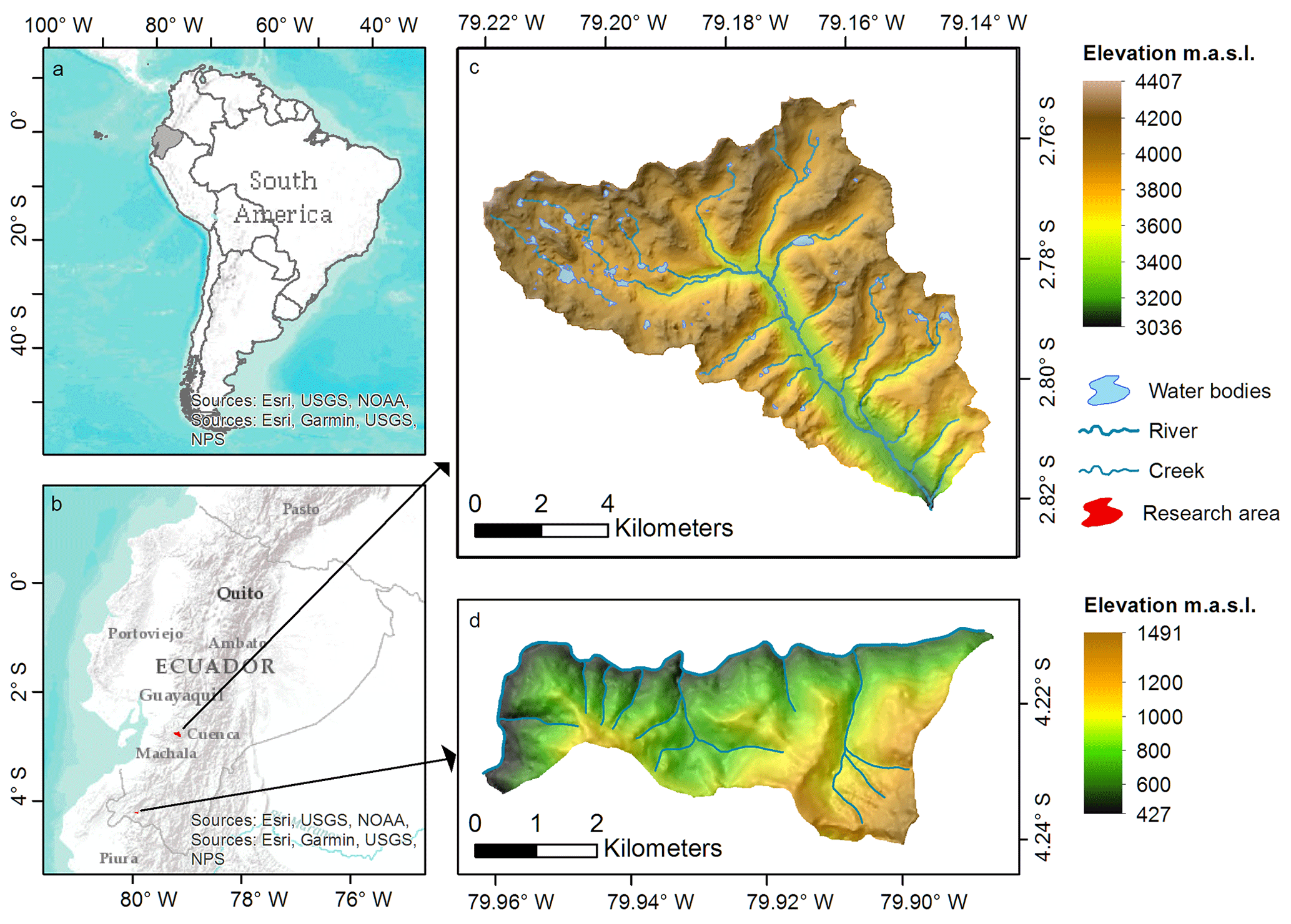
Figure 1Maps of (a) Ecuador within South America, (b) research areas within Ecuador, (c) Quinuas, and (d) Laipuna (overlaid with hill shading – light source from the north). Adapted from Ließ (2015). Topographical data were used with permission from the Ecuadorian Geographical Institute (2013; national base, scale 1:50 000), and further GIS data were provided by the NGO Nature and Culture International (NCI) and the municipal public agency ETAPA.
2.2 Soil data
To ensure representative data sets for both areas, sampling sites were selected using the “QC-arLUS” algorithm (Ließ, 2015). The algorithm divides a research area into strata, which represent characteristic landscape structures. Actual sampling site selection per stratum is limited to the accessible area.
For Quinuas and Laipuna, two sampling sites were chosen per landscape stratum, resulting in 46 sites for Quinuas and 55 for Laipuna. Soil profiles were excavated at these sites. However, due to laboratory constraints, samples for the determination of soil water retention were only taken from the topsoil. Water retention was measured in three replicate samples according to DIN EN ISO 11274:2014-07: hanging water columns of increasing length were applied to undisturbed 100 cm3 steel core samples. Four suction levels, expressed as the base 10 logarithm of the suction (pF), were simulated (suction shown in parentheses): pF 0 (−100 hPa), pF 0.5 (−100.5 hPa), pF 1.5 (−101.5 hPa), and pF 2.5 (−102.5 hPa). The high amount of organic matter in the Quinuas soil samples prevented water retention measurements at higher pF values. BD and SOC content were used as predictors for both research areas in order to develop the water retention PTFs, while PSD was only used for Laipuna. For BD measurements according to DIN EN ISO 11272:2017-07, undisturbed samples (three replicates) were oven-dried at 105 ∘C for 3 d. Disturbed samples (three replicates) were tested for carbonates with 10 % hydrochloric acid, sieved to 2 mm, and ground before SOC content determination using dry combustion (DIN EN 15936:2012-11). Disturbed samples from Laipuna were oven-dried at 40 ∘C, sieved to 2 mm, and PSD was determined according to DIN ISO 11277:2002-08 in two (sand fractions) and three (clay and silt fractions) replicate samples. Measurements distinguish the following particle size classes: clay (<2 µm), fine silt (2–6.3 µm), medium silt (6.3–20 µm), coarse silt (20–62 µm), fine sand (62–200 µm), medium sand (200–630 µm), and coarse sand (630–2000 µm). The high soil organic matter contents prevented PSD measurements in Quinuas.
As suggested by Guio Blanco et al. (2018), models built on the Quinuas data set could be improved by treating samples from mineral soils as outliers and removing them. For both research areas, only data pairs of response and predictor variables that were identified as multivariate outliers were removed. Tests for multivariate outliers were done by building hierarchical clusters using the “hclust” function from the “fastcluster” R package (Müller, 2018), version 3.4.4. To enhance comparability, models were trained on response variables scaled to the range [0, 1] following Eq. (1):
where x is the vector of the response variables of length j.
2.3 Boosted regression trees
The boosted regression trees (BRT) algorithm combines the regression trees and boosting machine-learning techniques. Tree models use decision rules, which involve the predictor variables, to recursively partition the response variable data into increasingly similar subgroups until terminal nodes are reached (Kuhn and Johnson, 2013). For each subgroup, the response variable values of the terminal regression tree nodes are averaged to be used for the prediction (James et al., 2017). The boosting machine-learning technique improves the overall model accuracy by combining a number of simple models (Witten et al., 2011).
To develop the PTFs, BRT models were trained using the “gbm” R package, version 2.1.3 (Ridgeway, 2017), which is based on stochastic gradient boosting from Friedman (2002). This boosting technique iteratively fits a number of simple regression tree models to random training data subsets. In each iteration a new regression tree is added to the model until many simple regression trees form a linear combination: the final BRT model. Each tree that is added improves the overall model performance. The first tree improves model performance the most; further regression trees are fitted with emphasis on observations that are predicted poorly by the existing model.
To apply a BRT model, usually up to four parameters are tuned: number of trees (n.trees), shrinkage, interaction depth, and bag fraction (e.g., Ottoy et al., 2017; Wang et al., 2017; Yang et al., 2016). Elith et al. (2008) provide a detailed analysis of their function: the n.trees parameter describes the number of regression tree models to be iteratively fitted; shrinkage defines the model's learning rate by scaling the outcome of each simple regression tree, thereby controlling its contribution to the final model; the interaction depth parameter controls the number of splits in each tree to divide the response variable data into subgroups; and the bag fraction parameter determines the size of the randomly selected data subsets. This is able to reduce the risk of overfitting (Friedman, 2002), but it may lower the model robustness (Elith et al., 2008). To develop PTFs for Quinuas and Laipuna, these four parameters were tuned following the steps described in Sect. 2.4 and 2.5.
2.4 Parameter tuning
Parameter tuning was done in two different ways: (1) by grid search and (2) by optimization, which involved applying the differential evolution algorithm. Grid search compares a certain number of predefined k dimensional parameter vectors. In order to reduce computing time, the number of predefined values of the k=4 parameters was limited to five for each. The selected values were based on the recommendations of Elith et al. (2008) and Ridgeway (2012), and they are summarized in Table 1. Finally, 5k different combinations of tuning parameter values, i.e., 625, were compared.
In contrast to this, the differential evolution optimization algorithm, developed by Storn and Price (1995), is able to search the multivariate space between defined upper and lower parameter limits. The parameter values are optimized by minimizing an objective function, which defines their suitability. The objective function is allowed to be stochastic and noisy and does not need to be differentiable or continuous (Mullen et al., 2011).
Following the evolutionary theory, this is done by repeating three steps for i iterations: mutation, crossover, and selection (Fig. 2). At first, an initial parent population of a number (v) of k-dimensional parameter vectors is generated randomly. With each iteration i, these vectors are changed by mutation and randomly mixed by crossover to generate a new population. Selection compares the objective function values belonging to the parent and the new vector to decide whether a new vector replaces its parent vector. Differential evolution was applied using the “DEoptim” R package, version 2.2.4 (Ardia et al., 2016). For each tuning parameter, optimization limits correspond to the maximum and minimum grid search values (Table 1). The number of vectors of size k=4 tuning parameters was set to v=100. The R package's default mutation strategy was used, which changes each parent vector by adding two summands: (1) the difference between two random parent vectors, and (2) the difference between the vector to be perturbed and the best vector found in the parent population. Summands were scaled by the factor 0.8. For crossover, the probability of randomly mixing the parent and the mutated vectors' elements was set to 50 %. To reduce computing time, the optimization process was stopped either after imax=10 iterations without improving the objective function or a maximum number of 200 iterations. Prior to the selection step, the discrete tuning parameter values (n.trees and interaction depth) were rounded, as the differential evolution algorithm treats all values as real numbers during mutation and crossover. To select the final tuning parameter values, grid search and differential evolution both minimized same objective function: the cross validated root-mean-squared error of parameter tuning (RMSET). The calculation of RMSET is explained in Sect. 2.5.

Figure 2Flowchart of the differential evolution algorithm. “OBJ” refers to the objective function, “p” refers to the parent population, “n” refers to the new population, “i” refers to the iteration, “imax” refers to the maximum number of iterations, and “v” refers to the number of vectors. Reprinted from Gebauer et al. (2019).
Table 1Tuning parameter values to be tested by grid search, and optimization limits required by the differential evolution algorithm.

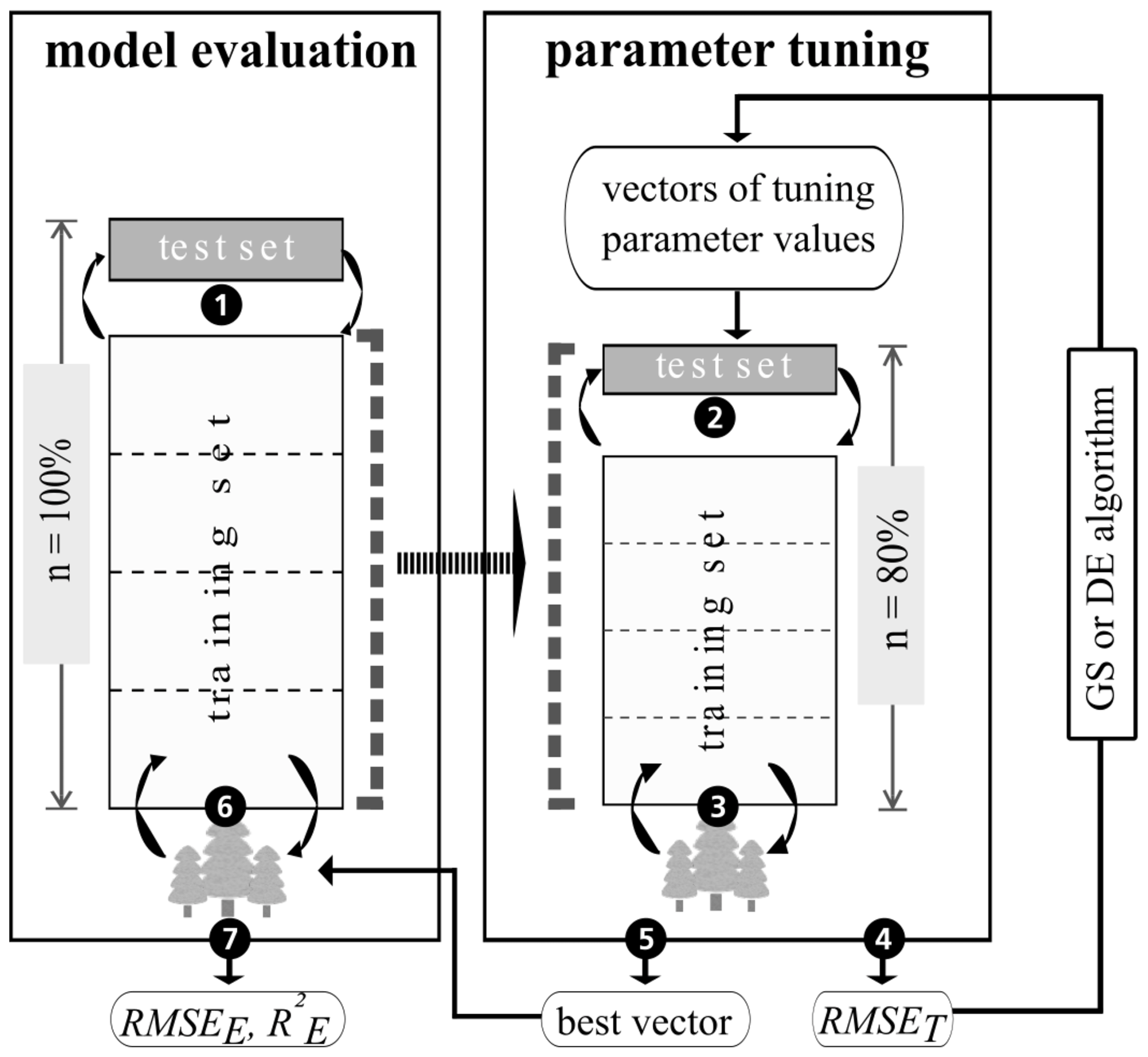
Figure 3Nested cross-validation approach comprising model evaluation and parameter tuning. Adapted from Guio Blanco et al. (2018). The tree icons symbolize BRT models, which are repeatedly (circular arrows) trained and tested on different data sets. The numbers within black circles refer to the steps described in Sect. 2.5. “RMSET” is the root-mean-squared error of parameter tuning, “RMSEE” is the root-mean-squared error of model evaluation, “” is the coefficient of determination of model evaluation, “GS” refers to grid search, and “DE” refers to the differential evolution.
2.5 Performance evaluation
In order to build robust models, we followed a nested cross-validation (CV) approach. Stratified five-fold CV was applied for two purposes: (1) to conduct robust parameter tuning on resampled data subsets using either grid search or the differential evolution algorithm, and (2) to evaluate the final performance of models built on tuned parameter values. CV provides error metrics with good bias and variance properties, is beneficial for small data sets, and avoids overfitting (Arlot and Celisse, 2009; James et al., 2017).
Following the steps shown in Fig. 3, stratified five-fold CV was implemented with five repetitions for model evaluation and one repetition for parameter tuning. In Step 1, the complete data set (n=100 %) was split into five folds with each of them (n=20 %) used once as the test set, leaving the remaining folds as the model training set. For resampling in parameter tuning (Step 2), each model training set was again subdivided in a similar fashion to Step 1. Each tuning parameter vector in grid search and the differential evolution algorithm was evaluated by the cross-validated RMSET (Step 3 and Step 4). By comparing the RMSET, the best vector of tuning parameter values for each model evaluation training set was selected and applied (Step 5 and Step 6). To assess model performance, the coefficient of determination () and the root-mean-squared error (RMSEE) of model evaluation were calculated by predicting the associated test set data (Step 7). To divide the data sets into folds, the “partition_cv_strat” function from the “sperrorest” R package, version 2.0.0 (Brenning et al., 2017), was applied, with three equal probability strata of the response variable's density function.

Figure 4Predictor variables for (1a, 1b) Quinuas (46 samples) and (2a–c) Laipuna (51 samples), showing the (1a, 2a) SOC content, (1b, 2b) bulk density, and (2c) particle size distribution displayed as a cumulative distribution function (mean values with standard deviation). High organic matter contents prevented measurements of the particle size distribution in Quinuas.
2.6 Comparison to existing PTFs
To further assess the BRT PTFs developed, their results were compared to predictions resulting from the application of existing PTFs. PTFs that were developed on different data sets, under conditions as similar as possible to those of Quinuas and Laipuna, were selected from the literature. If more than one PTF was provided per study, the one with the best reported performance was applied. For Laipuna, seven PTFs (Table 2) were chosen based on four criteria: (1) developed for tropical soils, (2) similar predictor variables, (3) regression equation provided, and (4) included in the peer-reviewed Clarivate Analytics' Web of Science database. To be able to apply the readily available equations with predictors of the Laipuna data set, it was necessary to convert the determined soil texture classes to the respective USDA classes. Following the approach of Shang (2013), texture conversion was done using spline interpolation. Because of different predictor variables, it is difficult to find organic PTFs applicable to the Quinuas data set. An exhaustive literature search only revealed the PTF from Boelter (1969), who related water retention at pF 0 to BD for temperate peat soils in northern Minnesota.
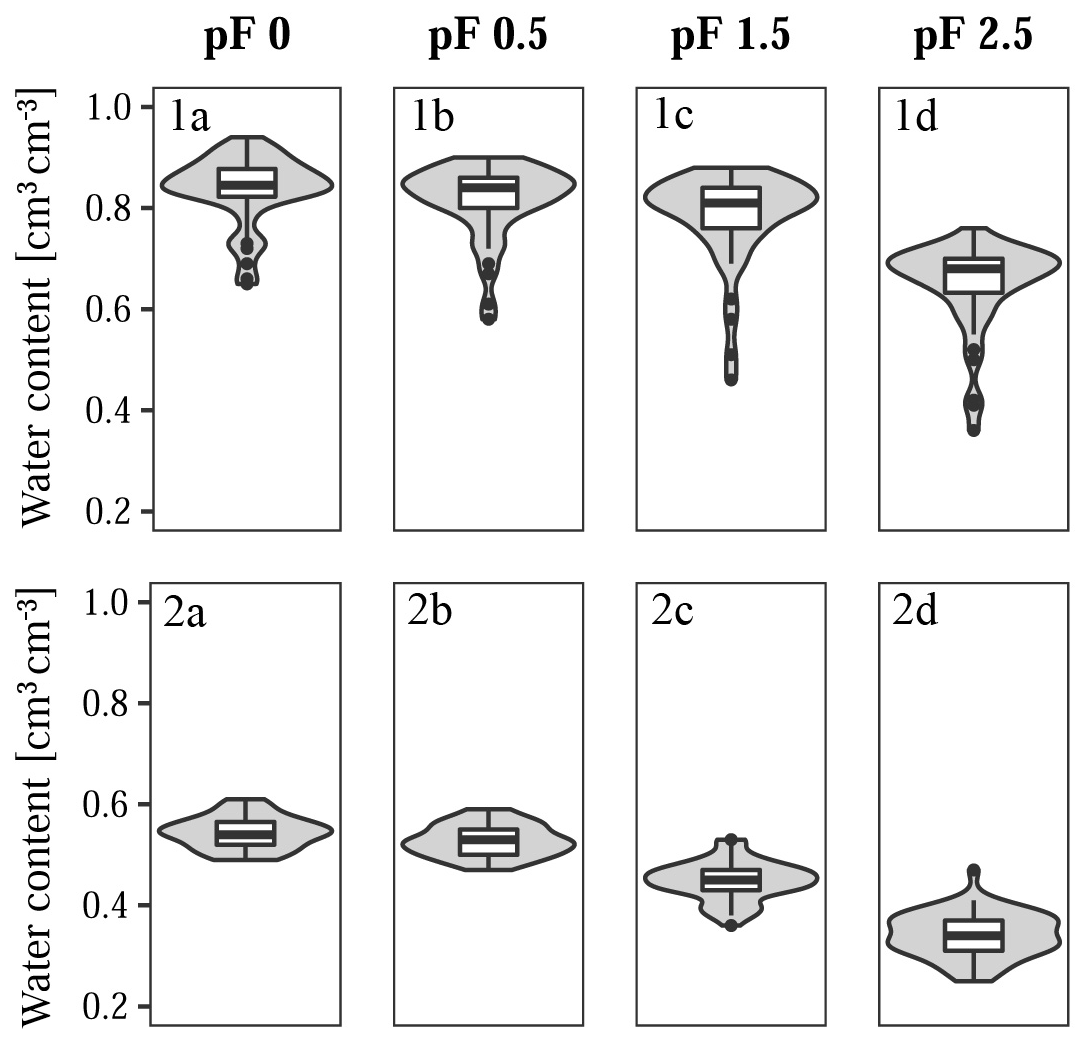
Figure 5Response variables for (1a–d) Quinuas (46 samples) and (2a–d) Laipuna (51 samples), showing water retention at (1a, 2a) pF 0, (1b, 2b) pF 0.5, (1c, 2c) pF 1.5, and (1d, 2d) pF 2.5.
3.1 Model input
For Laipuna, data pairs of four sampling sites were identified as multivariate outliers. After removing them, the data sets contained the predictor and response variables of 51 and 46 sampling sites for Laipuna and Quinuas, respectively. A summary of the remaining unscaled data is shown in Figs. 4 and 5.
As expected, both areas show huge differences regarding the values of response and predictor variables. BD values in Quinuas range from 64 to 807 kg m−3, while SOC values vary between 8.8 wt % and 46.4 wt %. SOC values are normally distributed, while BD data display a positive skew. Water retention ranges from 0.25 (pF 2.5) to 0.94 cm3 cm−3 (pF 0), decreasing by 22 % on average. While the data display a positive skew for pF 0, the data distribution for the other pF values shows a negative skew. For Laipuna, BD ranges between 1157 and 1727 kg m−3, displaying a distribution with a positive skew. The SOC content is normally distributed and varies between 0.4 wt % and 3.8 wt %. Clay content ranges between 17 % and 48 %, silt ranges between 24 % and 45 %, and sand ranges between 14 % and 50 %. Especially fine and medium silt show skewed distributions. Water retention values range between 0.25 (pF 2.5) and 0.61 cm3 cm−3 (pF 0). On average, they decrease by 37 % with increasing water tension. Data are skewed positively for pF 0 and negatively for pF 0.5. Quinuas soils go along with the low density, porous soils that are rich in organic material, which are found throughout the Paute River basin (Buytaert et al., 2007; Poulenard et al., 2003). Loosely bedded volcanic ash deposits explain the low BD values, which are are caused by low redox potentials and the presence of organometallic complexes inhibiting degradation processes (Buytaert et al., 2006a). Comparatively high water retention values can be attributed to the fact that the porous structure of Páramo soils is able to retain a lot of water (Buytaert et al., 2007). High soil organic matter contents are associated with soils characterized by a high water holding capacity (Buytaert et al., 2007), which explains the relatively small decrease in water retention with increasing water tension. Measured BD and SOC contents are in accordance with data observed for other Páramo regions (e.g., Buytaert et al., 2007, 2006b). The water retention values are also comparable to data obtained in other Páramo areas (Buytaert et al., 2005) and soils with high organic matter contents (Schwärzel et al., 2002, 2006). Extreme BD and water retention values (Figs. 4, 5) correspond to less frequent mineral soils with much lower SOC contents (Guio Blanco et al., 2018). As these values were expected to be reliable, they were not removed from the model input. The BD and SOC values measured in Laipuna correspond to other dry forest ecosystems (e.g., Conti et al., 2014; de Araújo Filho et al., 2017; Singh et al., 2015), whereas the PSD shows higher clay contents compared with the dry forest soils investigated by Cotler and Ortega-Larrocea (2006), Jha et al. (1996), and Sagar et al. (2003). Measured water retention values are higher than those obtained in a tropical dry forest in Brazil (Vasques et al., 2016), which is probably caused by the higher clay content enhancing the water holding capacity.

Figure 6Error metrics of the Quinuas BRT models, showing (1a–d) RMSEE and (2a–d) for (1a, 2a) pF 0, (1b, 2b) pF 0.5, (1c, 2c) pF 1.5, and (1d, 2d) pF 2.5. Each boxplot is based on five values resulting from five CV repetitions. GS refers to grid search, and DE refers to the differential evolution algorithm. Error metrics were calculated based on response variables scaled to the range [0, 1].
3.2 Model performance
The performance of the final models, which were built on parameters selected by grid search and the differential evolution algorithm, is demonstrated by the and RMSEE error metrics in Fig. 6 (Quinuas) and Fig. 7 (Laipuna) as well as by scatterplots comparing observed and predicted water retention values in Fig. 8 (Quinuas) and Fig. 9 (Laipuna). The error metrics and scatterplots are based on response variables scaled to the range [0, 1].
All grid search models resulted in very similar mean RMSEE values: between 0.20 (pF 1.5) and 0.22 (pF 0) for Quinuas and between 0.19 (pF 2.5) and 0.25 (pF 0, pF 0.5) for Laipuna. Differential evolution models trained on the Quinuas data sets correspond to mean RMSEE values ranging from 0.11 (pF 0) to 0.17 (pF 2.5). The Laipuna differential evolution models resulted in the same mean RMSEE values, ranging from 0.15 (pF 2.5) to 0.28 (pF 0). Mean values resulting from grid search varied between 0.03 (pF 0) and 0.09 (pF 1.5) for Quinuas and between 0.03 (pF 0.5, pF 2.5) and 0.05 (pF 1.5) for Laipuna. The differential evolution algorithm resulted in mean values increasing from 0.58 (pF 2.5) to 0.79 (pF 0) for Quinuas and from 0.35 (pF 0.5) to 0.68 (pF 0) for Laipuna. As demonstrated by the scatterplots, the grid search models roughly reproduced the mean water retention values, whereas the models with parameter tuning using differential evolution were able to explain more of the observations' variance.
The five grid search predictions for each observation (panels 1a–d in Figs. 8 and 9) cover a smaller range than the differential evolution predictions (panels 2a–d in Figs. 8 and 9). Specifically, the differential evolution results of the Laipuna pF 0 and pF 0.5 models are characterized by comparatively high variance. Caused by the better adjustment to the modeling problem, the differential evolution models show a higher predictive performance than the models tuned by grid search: mean values are up to 25 (Quinuas, pF 0) and 19 (Laipuna, pF 2.5) times higher, and the scaled RMSEE values are up to 2.1 (Quinuas, pF 0) and 1.3 (Laipuna, pF 2.5) times lower than those obtained by grid search. This corresponds to the scatterplots in Fig. 8 and Fig. 9: the largest difference between grid search and differential evolution can be recognized for the pF 0 (Quinuas) and pF 2.5 (Laipuna) models. The higher variability of the differential evolution predictions corresponds to the differential evolution tuning parameter values covering a wider range than those achieved by applying grid search (Sect. 3.3). For Quinuas, the decreasing predictive performance with increasing pF values can probably be attributed to the lack of further predictors. While the predictors BD and SOC are able to explain most of the water retention values at pF 0 to pF 1.5, the lack of predictors related to the soil matrix, e.g., PSD information, prevents further improvement for pF 2.5.
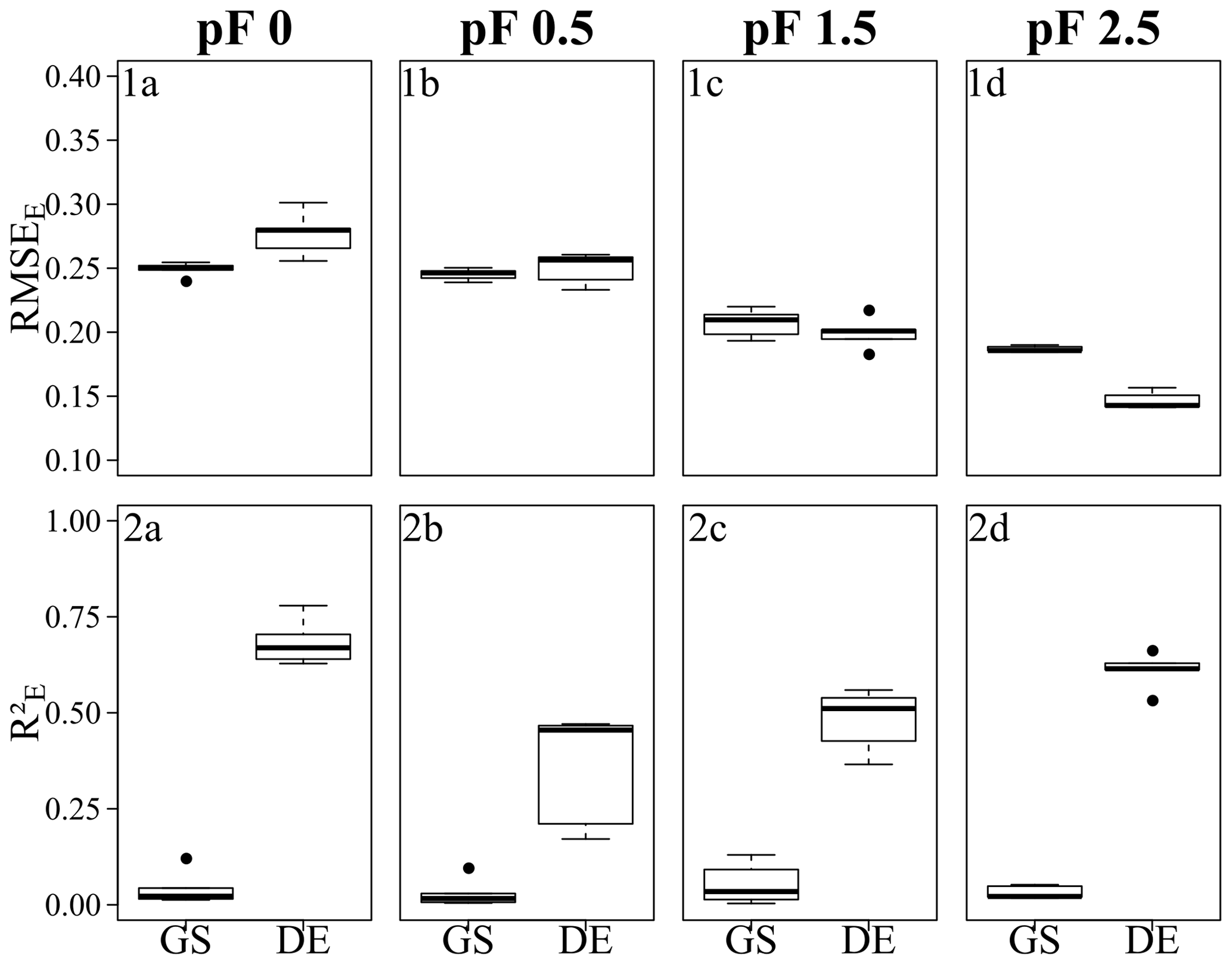
Figure 7Error metrics of the Laipuna BRT models, showing (1a–d) the RMSEE and (2a–d) the for (1a, 2a) pF 0, (1b, 2b) pF 0.5, (1c, 2c) pF 1.5, and (1d, 2d) pF 2.5. Each boxplot is based on five values resulting from five CV repetitions. GS refers to grid search, and DE refers to the differential evolution algorithm. Error metrics were calculated based on response variables scaled to the range [0, 1].
In pedometrics, studies with a direct comparison of grid search and mathematical optimization applied for parameter tuning in machine learning are scarce. In fact we are only aware of one application: Wu et al. (2016) compared both tuning strategies to train support vector machine (SVM) models for the prediction of soil contamination in Jiangxi Province, China. Their results are contradictory: overall, using optimization to tune three SVM parameters led to the best model performance. Unfortunately, the comparison with grid search was only applied to a reduced two-parameter tuning problem. Surprisingly, here, grid search outperformed the tested optimization algorithms. Unfortunately, the tuning of a different number of SVM parameters hampers direct comparison. Still, the results of Wu et al. (2016) show that a lucky selection of predefined parameter vectors can result in grid search outperforming optimization algorithms – in particular, if the number of optimization iterations is small. Overall, the more values that are tested during parameter tuning (grid search or optimization), the higher the probability of finding the global optimum. Wu et al. (2016) did not mention the number of iterations of the optimization algorithms, but we assume that increasing the number of iterations would have led to results that were at least as good as those achieved by grid search. Even though the benefits of optimization algorithms towards grid search are obvious, further direct comparisons of mathematical optimization algorithms and grid search applied for machine-learning parameter tuning in soil-related research questions are necessary.

Figure 8Comparison of predicted and observed water retention values for Quinuas, showing (1a–d) models with tuning by grid search and (2a–d) models with parameter tuning by differential evolution for (1a, 2a) pF 0, (1b, 2b) pF 0.5, (1c, 2c) pF 1.5, and (1d, 2d) pF 2.5. Each boxplot is based on five values resulting from five CV repetitions. Predicted and observed values were scaled to the range [0, 1].
Overall, the predictive power of all differential-evolution-based Quinuas models and the Laipuna pF 0 and 2.5 models are comparable to other studies. Botula et al. (2013), for example, obtained R2 values ranging from 0.32 to 0.68 (pF 0) and from 0.60 to 0.68 (pF 1.5) using the k-nearest neighbor algorithm for soil data originating from the Lower Congo. Keshavarzi et al. (2010) used an artificial neural network to predict water retention at different pF values for soils from the Qazvin Province in Iran. Haghverdi et al. (2012) used the same machine-learning technique on soils from northeastern and northern Iran. While Keshavarzi et al. (2010) gained R2 values of 0.77 (pF 2.5) and 0.72 (pF 4.2), Haghverdi et al. (2012) reached R2 values ranging from 0.81 to 0.95. In general, we expect model performance to improve when extreme values are removed from the model input or when larger data sets are used. Even though they were not identified as multivariate outliers, the low water retention values are underrepresented in the Quinuas data set. According to Guio Blanco et al. (2018), these values are primarily observed in the lower part of the river valley and include measurements from mineral soils. Furthermore, the question of whether different model algorithms are able to improve PTFs for both research areas needs to be tested.
3.3 Comparison with existing PTFs
Applying the existing PTFs with predictor variables sampled in Quinuas and Laipuna confirmed the good performance of the differential evolution BRT models. RMSE values of the respective PTFs are shown in Table 2. They were calculated by comparing the unscaled measured water retention of each soil profile to the water retention values calculated by applying the readily available PTFs. For Laipuna, mean RMSEE values of the differential-evolution-tuned BRT models were between 1.3 times (pF 2.5; Minasny and Hartemink, 2011, and Tomasella et al., 2000) and 9.3 times (pF 1.5; Barros et al., 2013) better (Table 2). For Quinuas, the application of the differential evolution BRT models resulted in a mean RMSEE of 0.03, whereas applying the PTF of Boelter (1969) only resulted in an RMSE of 1.86. For BD values higher than 370 kg m−3, the predictions even became negative. The high RMSE value is assumed to have been caused by large differences between the temperate organic soils in Minnesota and the soils in Quinuas. This underlines the necessity of developing water retention PTFs specifically for tropical organic soils.
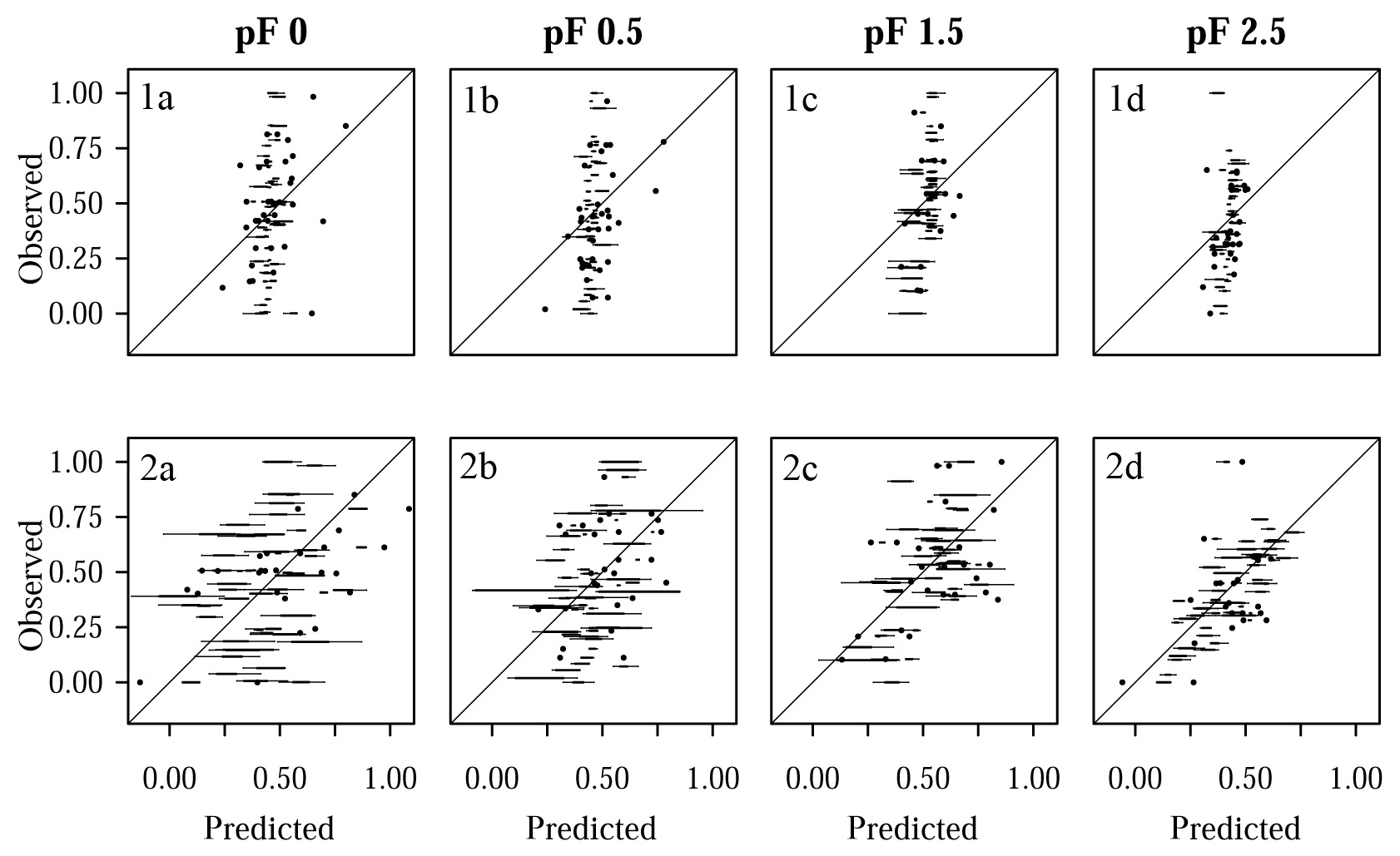
Figure 9Comparison of predicted and observed water retention values for Laipuna, showing (1a–d) models with tuning by grid search and (2a–d) models with parameter tuning by differential evolution for (1a, 2a) pF 0, (1b, 2b) pF 0.5, (1c, 2c) pF 1.5, and (1d, 2d) pF 2.5. Each boxplot is based on five values resulting from five CV repetitions. Predicted and observed values were scaled to the range [0, 1].
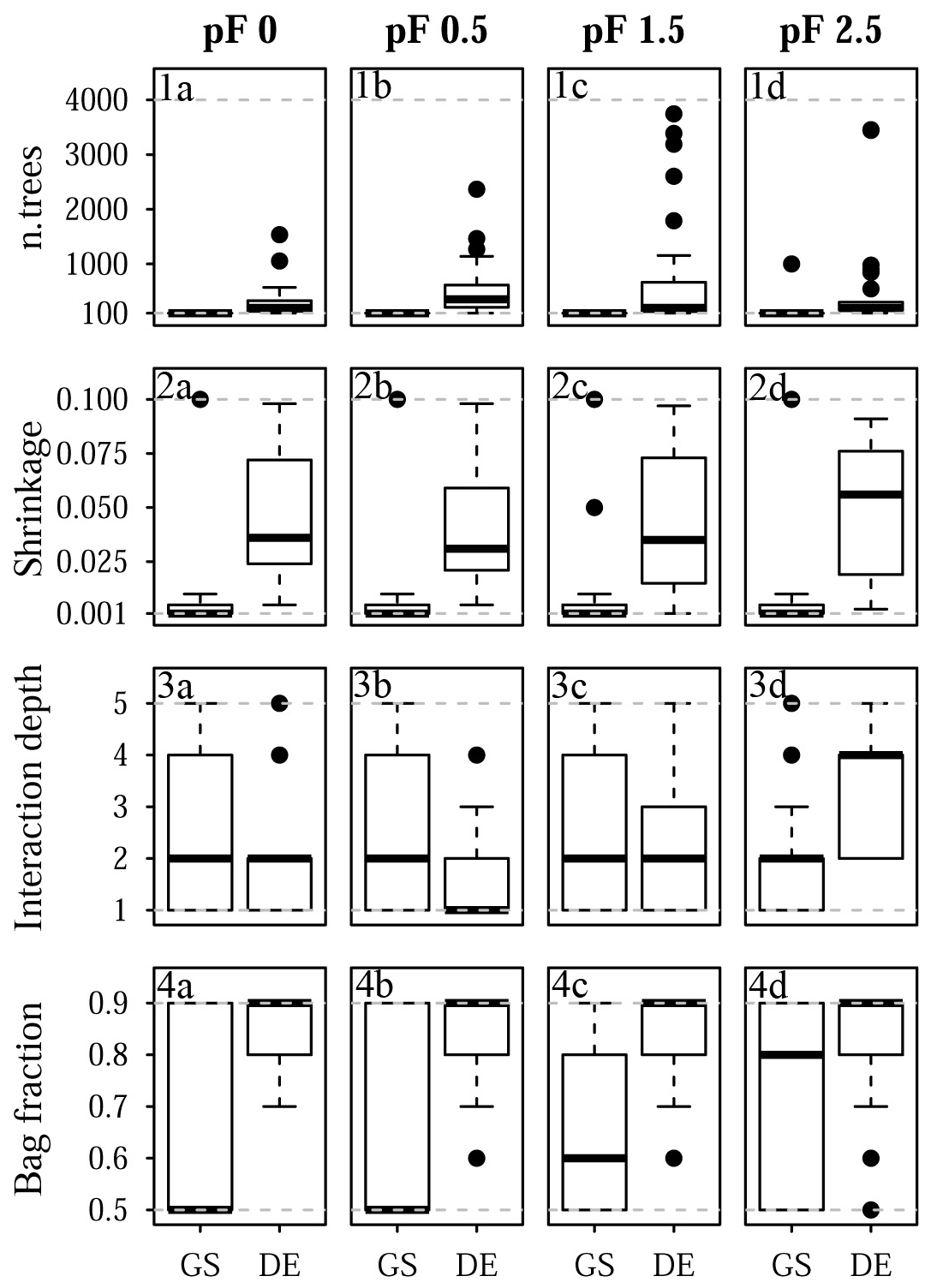
Figure 10Selected tuning parameter values for Quinuas: (1a–d) n.trees, (2a–d), shrinkage, (3a–d) interaction depth, and (4a–d) bag fraction for (1a, 2a, 3a, 4a) pF 0, (1b, 2b, 3b, 4b) pF 0.5, (1c, 2c, 3c, 4c) pF 1.5, and (1d, 2d, 3d, 4d) pF 2.5. Each boxplot is based on 25 values corresponding to the five-fold CV with five repetitions. Dashed gray lines indicate the chosen optimization limits. GS refers to grid search, and DE refers to the differential evolution algorithm.
Table 2Unscaled root-mean-squared errors for the tested PTFs. The best results for each matric potential are shown in bold. BRT PTF results are averaged.

∗ Applied to predict parameters of the Van Genuchten equation first.
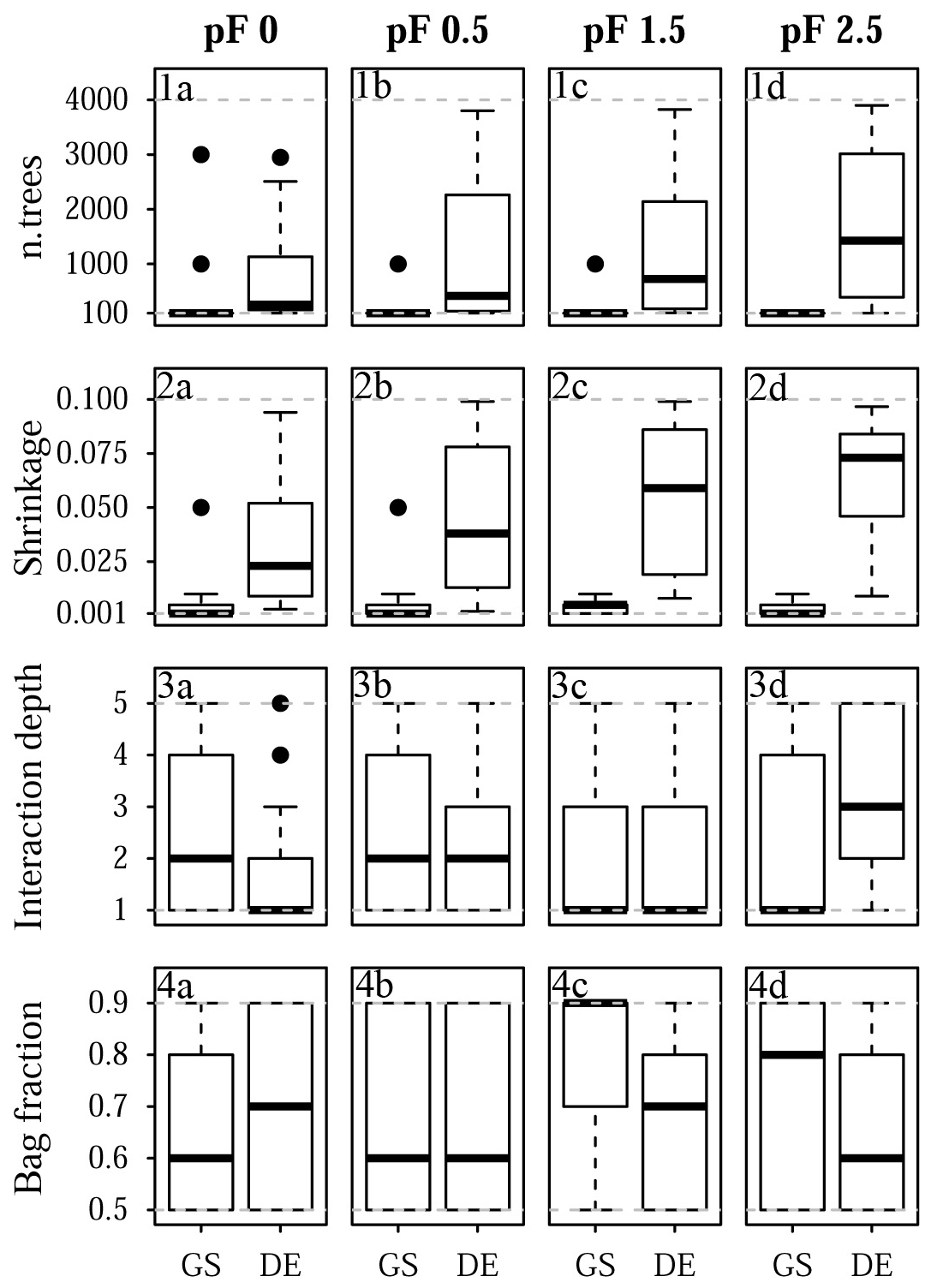
Figure 11Selected tuning parameter values for Laipuna: (1a–d) n.trees, (2a–d) shrinkage, (3a–d), interaction depth, and (4a–d) bag fraction for (1a, 2a, 3a, 4a) pF 0, (1b, 2b, 3b, 4b) pF 0.5, (1c, 2c, 3c, 4c) pF 1.5, and (1d, 2d, 3d, 4d) pF 2.5. Each boxplot is based on 25 values corresponding to the five-fold CV with five repetitions. Dashed gray lines indicate the chosen optimization limits. GS refers to grid search, and DE refers to the differential evolution algorithm.
3.4 Model parameters
The final tuning parameter values obtained by grid search and the differential evolution algorithm are summarized in Fig. 10 (Quinuas) and Fig. 11 (Laipuna). A total of 625 previously defined parameter vectors were compared using grid search. On average, 31 (pF 0, 0.5), 33 (pF 1.5), and 28 (pF 2.5) iterations of the differential evolution algorithm were necessary to find the optimal tuning parameter values for the Quinuas models. For Laipuna, 32 (pF 0), 28 (pF 0.5), 25 (pF 1.5), and 22 (pF 2.5) iterations were needed.
Differences between the parameter-tuning techniques are most distinct for n.trees and shrinkage. Neglecting outliers, values obtained by the differential evolution algorithm cover a wider range than those resulting from grid search: while n.trees was set to the lowest tested value (100) by grid search in most cases, the differential evolution algorithm resulted in mean n.trees values (± standard deviation) ranging from 310±321 (pF 0) to 810±1132 (pF 1.5) for Quinuas and from 727±851 (pF 0) to 1688±1345 (pF 2.5) for Laipuna. Therefore, the mean n.trees values obtained by differential evolution parameter tuning are more than 5 (Quinuas) and more than 10 times (Laipuna) higher than the mean grid search values. Neglecting extreme values, the shrinkage values resulting from the differential evolution algorithm also cover a wider range than the values obtained by the grid search tuning technique. For both areas, the shrinkage values were usually set to 0.001 or 0.01 by grid search, whereas applying the differential evolution algorithm resulted in mean shrinkage values from 0.040±0.028 (pF 0.5) to 0.047±0.030 (pF 2.5) for Quinuas and from 0.034±0.03 (pF 0) to 0.062±0.027 (pF 2.5) for Laipuna. On average, the differential evolution shrinkage values are approximately 14 (Quinuas) and 17 (Laipuna) times higher than those obtained by grid search.
The observed pattern is more complex for the other two tuning parameters: interaction depth and bag fraction. Although the selected parameter ranges differ for most pF values, the median interaction depth values are the same for half of the cases for grid search and tuning using the differential evolution algorithm. The median of the selected bag fraction is at the upper limit for the Quinuas models that were tuned by the differential evolution algorithm, whereas grid search resulted in median bag fraction values at the lower limit in two cases. The Laipuna bag fraction values do not show this pronounced difference between grid search and tuning using the differential evolution algorithm. The selected tuning parameter values correspond to the differential-evolution-based models having more predictive power than those adapted by the common grid search approach.
Usually higher n.trees values, as received from the differential evolution algorithm, are known to improve model performance (Elith et al., 2008). However, according to the results of Elith et al. (2008), using more trees causes the shrinkage parameter to get smaller. The comparatively high differential evolution shrinkage values are an indication of the n.trees values still being too small. For both areas, the differential evolution values for n.trees and shrinkage, which cover a wider range than the grid search results, are assumed to be caused by an incomplete optimization stemming from not using enough iterations or the algorithm being stuck in a local optimum. This corresponds to the high prediction variability of the final differential evolution models derived for Laipuna (Fig. 9).
It should be noted that model performance depends on the combination of parameter values. However, as n.trees and shrinkage control how precisely the model learns the input data structure, these parameters are assumed to be more important than interaction depth and bag fraction. In this case, there would not even be an optimum for the latter two parameters. Especially for Laipuna, this explains the interaction depth and bag fraction values of both tuning techniques covering the whole range of possible values. The bag fraction differences between differential evolution and grid search tuning remain unexplained. For both parameter-tuning techniques, increasing the number of parameter values to be tested enhances the probability of finding the global optimum. For grid search, this can be realized by increasing the number of values to be compared for each tuning parameter. Increasing the number of iterations and starting with larger and therefore more heterogeneous initial populations is expected to do the same for differential evolution. This is assumed to result in less variable differential evolution results.
However, for tuning continuous parameters, it is impossible to know the necessary number of iterations in advance. Accordingly, a trade-off between computing time and the probability of finding the global optimum has to be made for any parameter-tuning technique. In addition to increasing the number of iterations and the number of initial vectors, the risk of the differential evolution algorithm getting stuck in a local optimum can also be reduced by changing the parameters “crossover probability” and the “mutation scaling factor” as well as applying another mutation strategy (Das and Suganthan, 2011). To overcome the problem of choosing the right control parameters as well as the mutation strategy, self-adaptive differential evolution algorithms (e.g., Nahvi et al., 2016; Pierezan et al., 2017; Qin et al., 2009), which are able to automatically adjust their settings during the optimization process, could be applied in future studies. Furthermore, a larger, high quality model input would result in more explicit relationships between response and predictor variables that can be detected and reproduced more easily by the BRT models. This is assumed to reduce the probability of the differential evolution algorithm getting stuck into a local optimum as well as the number of iterations required. In general, the superiority of differential evolution needs to be verified by applying it to further machine-learning algorithms and applications and by comparing it to further parameter-tuning techniques.
We successfully developed new PTFs for two tropical mountain regions. The comparison with readily available PTFs showed their high performance with respect to predicting soil water retention for the soils in these areas. This is of particular importance for soil hydrological modeling. The applicability of the two PTFs in other areas with similar soils still has to be tested. The PTF developed for the Páramo area is novel, as PTFs for tropical organic soils under volcanic influence have been unavailable to date.
Furthermore, our study presents the first successful application of parameter tuning by differential evolution in PTF development. The comparison with the standard grid search technique revealed the superiority of the differential evolution algorithm and emphasizes the importance of parameter tuning for the successful application of machine-learning models. Of course, this finding has to be confirmed by further applications in pedometrics, including different machine-learning algorithms. We hope to promote the implementation of optimization algorithms within the pedometrics community, especially for tuning of machine-learning algorithms with continuous parameters.
The PTFs developed as well as the underlying data sets are available from https://doi.org/10.17605/OSF.IO/7UBWY (Ließ et al., 2020).
VBG and ML carried out the soil sampling and lab measurements. AG, ML, and ME were responsible for the model setup, data analysis, and writing the paper. ML was responsible for the conceptual embedding.
The authors declare that they have no conflict of interest.
This research was funded by the German Research Foundation (DFG) as part of “Platform for Biodiversity and Ecosystem Monitoring and Research in South Ecuador” (grant no. PAK 825, LI 2360/1-1). Logistic support from the NGO Nature and Culture International (NCI) and the municipal public agency ETAPA is gratefully acknowledged.
This research has been supported by the German Research Foundation (DFG; grant no. PAK 825, LI 2360/1-1).
This paper was edited by Jan Vanderborght and reviewed by two anonymous referees.
Ardia, D., Mullen, K., Peterson, B., Ulrich, J., and Boudt, K.: R package “DEoptim”: Global Optimization by Differential Evolution, available at: https://cran.r-project.org/package=DEoptim (last access: 5 July 2019), 2016.
Arlot, S. and Celisse, A.: A survey of cross-validation procedures for model selection, Stat. Surv., 4, 40–79, https://doi.org/10.1214/09-SS054, 2009.
Babangida, N. M., Ul Mustafa, M. R., Yusuf, K. W., Isa, M. H., and Baig, I.: Evaluation of low degree polynomial kernel support vector machines for modelling Pore-water pressure responses, Matec. Web Conf., 59, 6 pp., https://doi.org/10.1051/matecconf/20165904003, 2016.
Barros, A. H. C., Lier, Q. de J. van, Maia, A. de H. N., and Scarpare, F. V.: Pedotransfer functions to estimate water retention parameters of soils in northeastern Brazil, Rev. Bras. Ciência do Solo, 37, 379–391, https://doi.org/10.1590/S0100-06832013000200009, 2013.
Bendix, J., Gämmerler, S., Reudenbach, C., and Bendix, A.: A case study on rainfall dynamics during El Niño/La Niña 1997/99 in Ecuador and surrounding areas as inferred from GOES-8 and TRMM-PR observations, Erdkunde, 57, 81–93, https://doi.org/10.3112/erdkunde.2003.02.01, 2003.
Bendix, J., Trachte, K., Palacios, E., Rollenbeck, R., Göttlicher, D., Nauss, T., and Bendix, A.: El Niño meets La Niña-anomalous rainfall patterns in the “traditional” El Niño region of Southern Ecuador, Erdkunde, 65, 151–167, https://doi.org/10.3112/erdkunde.2011.02.04, 2011.
Best, B. J. and Kessler, M.: Biodiversity and Conservation in Tumbesian Ecuador and Peru, BirdLife International, Cambridge, UK, 218 pp., 1995.
Bhadra, T., Bandyopadhyay, S., and Maulik, U.: Differential Evolution Based Optimization of SVM Parameters for Meta Classifier Design, Proc. Technol., 4, 50–57, https://doi.org/10.1016/j.protcy.2012.05.006, 2012.
Boelter, D. H.: Physical Properties of Peats as Related to Degree of Decomposition, Soil Sci. Soc. Amer. Proc., 33, 606–609, 1969.
Botula, Y.-D., Nemes, A., Mafuka, P., Van Ranst, E., and Cornelis, W. M.: Prediction of Water Retention of Soils from the Humid Tropics by the Nonparametric -Nearest Neighbor Approach, Vadose Zo. J., 12, 1–17, https://doi.org/10.2136/vzj2012.0123, 2013.
Botula, Y. D., Cornelis, W. M., Baert, G., and Van Ranst, E.: Evaluation of pedotransfer functions for predicting water retention of soils in Lower Congo (D. R. Congo), Agr. Water Manag., 111, 1–10, https://doi.org/10.1016/j.agwat.2012.04.006, 2012.
Botula, Y. D., Van Ranst, E., and Cornelis, W. M.: Pedotransfer Functions to Predict Water Retention for Soils of the Humid Tropics: A Review, Rev. Bras. Ciência Do Solo, 38, 679–698, https://doi.org/10.1590/S0100-06832014000300001, 2014.
Brenning, A., Schratz, P., and Hermann, T.: R package “sperrorest”: Perform Spatial Error Estimation and Variable Importance in Parallel, available at: https://cran.r-project.org/web/packages/sperrorest, last access: 13 June 2017.
Brus, D. J., Yang, R. M., and Zhang, G. L.: Three-dimensional geostatistical modeling of soil organic carbon: A case study in the Qilian Mountains, China, Catena, 141, 46–55, https://doi.org/10.1016/j.catena.2016.02.016, 2016.
Buytaert, W., Wyseure, G., De Bièvre, B., and Deckers, J.: The effect of land-use changes on the hydrological behaviour of Histic Andosols in south Ecuador, Hydrol. Process., 19, 3985–3997, https://doi.org/10.1002/hyp.5867, 2005.
Buytaert, W., Deckers, J., and Wyseure, G.: Description and classification of nonallophanic Andosols in south Ecuadorian alpine grasslands (páramo), Geomorphology, 73, 207–221, https://doi.org/10.1016/j.geomorph.2005.06.012, 2006a.
Buytaert, W., Celleri, R., Willems, P., Bièvre, B. D., and Wyseure, G.: Spatial and temporal rainfall variability in mountainous areas: A case study from the south Ecuadorian Andes, J. Hydrol., 329, 413–421, https://doi.org/10.1016/j.jhydrol.2006.02.031, 2006b.
Buytaert, W., Deckers, J., and Wyseure, G.: Regional variability of volcanic ash soils in south Ecuador: The relation with parent material, climate and land use, Catena, 70, 143–154, https://doi.org/10.1016/j.catena.2006.08.003, 2007.
Carr, S., Garnett, R., and Lo, C.: BASC: Applying Bayesian optimization to the search for global minima on potential energy surfaces, in: Proceedings of the 33rd International Conference on Machine Learning, 48, 898–907, 2016.
Carrillo-Rojas, G., Silva, B., Córdova, M., Célleri, R., and Bendix, J.: Dynamic mapping of evapotranspiration using an energy balance-based model over an andean páramo catchment of southern ecuador, Remote Sens., 8, 1–24, https://doi.org/10.3390/rs8020160, 2016.
Celleri, R., Willems, P., Buytaert, W., and Feyen, J.: Space-time rainfall variability in the Paute Basin, Ecuadorian Andes, Hydrol. Process., 21, 3316–3327, https://doi.org/10.1002/hyp.6575, 2007.
Chen, W., Panahi, M., and Pourghasemi, H. R.: Performance evaluation of GIS-based new ensemble data mining techniques of adaptive neuro-fuzzy inference system (ANFIS) with genetic algorithm (GA), differential evolution (DE), and particle swarm optimization (PSO) for landslide spatial modelling, Catena, 157, 310–324, https://doi.org/10.1016/j.catena.2017.05.034, 2017.
Conti, G., Pérez-Harguindeguy, N., Quètier, F., Gorné, L. D., Jaureguiberry, P., Bertone, G. A., Enrico, L., Cuchietti, A., and Díaz, S.: Large changes in carbon storage under different land-use regimes in subtropical seasonally dry forests of southern South America, Agric. Ecosyst. Environ., 197, 68–76, https://doi.org/10.1016/j.agee.2014.07.025, 2014.
Cotler, H. and Ortega-Larrocea, M. P.: Effects of land use on soil erosion in a tropical dry forest ecosystem, Chamela watershed, Mexico, Catena, 65, 107–117, https://doi.org/10.1016/j.catena.2005.11.004, 2006.
Crespo, P. J., Feyen, J., Buytaert, W., Bücker, A., Breuer, L., Frede, H. G., and Ramírez, M.: Identifying controls of the rainfall-runoff response of small catchments in the tropical Andes (Ecuador), J. Hydrol., 407, 164–174, https://doi.org/10.1016/j.jhydrol.2011.07.021, 2011.
Das, S. and Suganthan, P. N.: Differential Evolution: A Survey of the State-of-the-Art, IEEE T. Evol. Comput., 15, 4–31, https://doi.org/10.1109/TEVC.2010.2059031, 2011.
de Araújo Filho, R. N., dos Santos Freire, M. B. G., Wilcox, B. P., West, J. B., Freire, F. J., and Marques, F. A.: Recovery of carbon stocks in deforested caatinga dry forest soils requires at least 60 years, For. Ecol. Manage., https://doi.org/10.1016/j.foreco.2017.10.002, 2017.
DIN EN 15936:2012-11: Sludge, treated biowaste, soil and waste – Determination of total organic carbon (TOC) by dry combustion, https://doi.org/10.31030/1866720, 2012.
DIN EN ISO 11272:2017-07: Soil quality – Determination of dry bulk density, https://doi.org/10.31030/2581910, 2017.
DIN EN ISO 11274:2014-07: Soil quality – Determination of the water-retention characteristic – Laboratory methods, https://doi.org/10.31030/2143359, 2014.
DIN ISO 11277:2002-08: Soil quality – Determination of particle size distribution in mineral soil material – Method by sieving and sedimentation, https://doi.org/10.31030/9283499, 2002.
Elith, J., Leathwick, J. R., and Hastie, T.: A working guide to boosted regression trees, J. Anim. Ecol., 77, 802–813, https://doi.org/10.1111/j.1365-2656.2008.01390.x, 2008.
Friedman, J. H.: Stochastic gradient boosting, Comput. Stat. Data Anal., 38, 367–378, https://doi.org/10.1016/S0167-9473(01)00065-2, 2002.
Gebauer, A., Brito Gómez, V. M., and Ließ, M.: Optimisation in machine learning: An application to topsoil organic stocks prediction in a dry forest ecosystem, Geoderma, 354, 113846, https://doi.org/10.1016/j.geoderma.2019.07.004, 2019.
Guio Blanco, C. M., Brito Gomez, V. M., Crespo, P., and Ließ, M.: Spatial prediction of soil water retention in a Páramo landscape: Methodological insight into machine learning using random forest, Geoderma, 316, 100–114, https://doi.org/10.1016/j.geoderma.2017.12.002, 2018.
Haghverdi, A., Cornelis, W. M., and Ghahraman, B.: A pseudo-continuous neural network approach for developing water retention pedotransfer functions with limited data, J. Hydrol., 442, 46–54, https://doi.org/10.1016/j.jhydrol.2012.03.036, 2012.
Heung, B., Ho, H. C., Zhang, J., Knudby, A., Bulmer, C. E., and Schmidt, M. G.: An overview and comparison of machine-learning techniques for classification purposes in digital soil mapping, Geoderma, 265, 62–77, https://doi.org/10.1016/j.geoderma.2015.11.014, 2016.
James, G., Witten, D., Hastie, T., and Tibshirani, R.: An Introduction to Statistical Learning, edited by: Casella, G., Fienberg, S., and Olkin, I., Springer, New York, Heidelberg, Dordrecht, London, 426 pp., 2017.
Jayanth, J., Koliwad, S., and Ashok Kumar, T.: Classification of remote sensed data using Artificial Bee Colony algorithm, Egypt. J. Remote Sens. Sp. Sci., 18, 119–126, https://doi.org/10.1016/j.ejrs.2015.03.001, 2015.
Jha, P. B., Singh, J. S., and Kashyap, A. K.: Dynamics of viable nitrifier community and nutrient availability in dry tropical forest habitat as affected by cultivation and soil texture, Plant Soil, 180, 277–285, https://doi.org/10.1007/BF00015311, 1996.
Kang-Ping, W., Huang, L., Zhou, C.-G., and Pang, W.: Particle swarm optimization for traveling salesman problem, in: International Conference on Machine Learning and Cybernetics, 1583–1585, 2003.
Keshavarzi, A., Sarmadian, F., Sadeghnejad, M., and Pezeshki, P.: Developing Pedotransfer Functions for Estimating some Soil Properties using Artificial Neural Network and Multivariate Regression Approaches, Int. J. Environ. Earth Sci., 1, 31–37, 2010.
Khlosi, M., Alhamdoosh, M., Douaik, A., Gabriels, D., and Cornelis, W. M.: Enhanced pedotransfer functions with support vector machines to predict water retention of calcareous soil, Eur. J. Soil Sci., 67, 276–284, https://doi.org/10.1111/ejss.12345, 2016.
Korus, M., Sławiński, C., and Witkowska-Walczak, B.: Attempt of water retention characteristics estimation as pedotransfer function for organic soils, Int. Agrophysics, 21, 249–254, 2007.
Kuhn, M. and Johnson, K.: Applied Predictive Modeling, Springer, New York, Heidelberg, Dordrecht, London, 600 pp., 2013.
Lamorski, K., Pachepsky, Y., Sławi´nski, C., and Walczak, R. T.: Using Support Vector Machines to Develop Pedotransfer Functions for Water Retention of Soils in Poland, Soil Sci. Soc. Am. J., 72, 115 1243, https://doi.org/10.2136/sssaj2007.0280N, 2008.
Ließ, M.: Sampling for regression-based digital soil mapping: Closing the gap between statistical desires and operational applicability, Spat. Stat., 13, 106–122, https://doi.org/10.1016/j.spasta.2015.06.002, 2015.
Ließ, M., Gebauer, A., Ellinger, M., Brito Gomez, V. M., and Guio Blanco, C. M.: DATA and PTFs: Development of pedotransfer functions for water retention in tropical mountain soilscapes: Spotlight on parameter tuning in machine learning, https://doi.org/10.17605/OSF.IO/7UBWY, 2020.
Linares-Palomino, R., Kvist, L. P., Aguirre-Mendoza, Z., and Gonzales-Inca, C.: Diversity and endemism of woody plant species in the Equatorial Pacific seasonally dry forests, Biodivers. Conserv., 19, 169–185, https://doi.org/10.1007/s10531-009-9713-4, 2009.
Liu, H. C. and Huang, J. S.: Pattern recognition using evolution algorithms with fast simulated annealing, Pattern Recognit. Lett., 19, 403–413, https://doi.org/10.1016/S0167-8655(98)00025-7, 1998.
Maggi, S.: Estimating water retention characteristic parameters using differential evolution, Comput. Geotech., 86, 163–172, https://doi.org/10.1016/j.compgeo.2016.12.025, 2017.
Martinez-Soltero, E. G. and Hernandez-Barragan, J.: Robot Navigation Based on Differential Evolution, IFAC-PapersOnLine, 51, 350–354, https://doi.org/10.1016/j.ifacol.2018.07.303, 2018.
McBratney, A., de Gruijter, J., and Bryce, A.: Pedometrics timeline, Geoderma, 338, 568–575, https://doi.org/10.1016/j.geoderma.2018.11.048, 2019.
Minasny, B. and Hartemink, A. E.: Predicting soil properties in the tropics, Earth-Sci. Rev., 106, 52–62, https://doi.org/10.1016/j.earscirev.2011.01.005, 2011.
Moreira, L. F. F., Righetto, A. M., and Medeiros, V. M. D. A.: Soil Hydraulics Properties Estimation by Using Pedotransfer Functions in a Northeastern Semiarid Zone Catchment, Brazil, in: International congress on environmental modelling and software, Osnabrück, 1529 pp., 2004.
Morris, P. J., Baird, A. J., Eades, P. A., and Surridge, B. W. J.: Controls on Near-Surface Hydraulic Conductivity in a Raised Bog, Water Resour. Res., 1531–1543, https://doi.org/10.1029/2018WR024566, 2019.
Mullen, K., Ardia, D., Gil, D., Windover, D., and Cline, J.: DEoptim?: An R Package for Global Optimization by Differential Evolution, J. Stat. Softw., 40, 1–26, https://doi.org/10.18637/jss.v040.i06, 2011.
Müller, D.: fastcluster: Fast Hierarchical, Agglomerative Clustering Routines for R and Python, J. Stat. Softw., 53, 1–18, https://doi.org/10.18637/jss.v053.i09, 2013.
Nahvi, B., Habibi, J., Mohammadi, K., and Shamshirband, S.: Using self-adaptive evolutionary algorithm to improve the performance of an extreme learning machine for estimating soil temperature, Comput. Electron. Agric., 124, 150–160, https://doi.org/10.1016/j.compag.2016.03.025, 2016.
Ottoy, S., Van Meerbeek, K., Sindayihebura, A., Hermy, M., and Van Orshoven, J.: Assessing top- and subsoil organic carbon stocks of Low-Input High-Diversity systems using soil and vegetation characteristics, Sci. Total Environ., 589, 153–164, https://doi.org/10.1016/j.scitotenv.2017.02.116, 2017.
Ou, Z.: Differential evolution's application to estimation of soil water retention parameters, Agronomy, 5, 464–475, https://doi.org/10.3390/agronomy5030464, 2015.
Ozaki, Y., Yano, M., and Onishi, M.: Effective hyperparameter optimization using Nelder-Mead method in deep learning, IPSJ Trans. Comput. Vis. Appl., 9, 20, https://doi.org/10.1186/s41074-017-0030-7, 2017.
Pachepsky, Y. A. and Rawls, W. J. (Eds).: Development of Pedotransfer Functions in Soil Hydrology, Elsevier Science, Developments in Soil Science, Amsterdam, 512 pp., 2004.
Patil, N. G. and Singh, S. K.: Pedotransfer Functions for Estimating Soil Hydraulic Properties: A Review, Pedosphere, 26, 417–430, https://doi.org/10.1016/S1002-0160(15)60054-6, 2016.
Peters, T. and Richter, M.: Climate Station Data Reserva Laipuna mountain peak, available at: http://www.tropicalmountainforest.org/data_pre.do?citid=963 (last access: 6 September 2017), 2011.
Peters, T. and Richter, M.: Climate Station Data Reserva Laipuna valley, available at: http://www.tropicalmountainforest.org/data_pre.do?citid=964 (last access: 6 September 2017), 2011.
Pierezan, J., Freire, R. Z., Weihmann, L., Reynoso-Meza, G., and dos Santos Coelho, L.: Static force capability optimization of humanoids robots based on modified self-adaptive differential evolution, Comput. Oper. Res., 84, 205–215, https://doi.org/10.1016/j.cor.2016.10.011, 2017.
Poulenard, J., Podwojewski, P., and Herbillon, A. J.: Characteristics of non-allophanic Andisols with hydric properties from the Ecuadorian páramos, Geoderma, 117, 267–281, https://doi.org/10.1016/S0016-7061(03)00128-9, 2003.
Price, K., Storn, R., and Lampinen, J.: Differential Evolution, A Practical Approach to Global Optimization, edited by: Rozenberg, G., Bäck, T., Eiben, A. E., Kok, J. N., and Spaink, H., Springer, Berlin, Heidelberg, New York, 539 pp., 2005.
Qin, A. K., Huang, V. L., and Suganthan, P. N.: Adaptation for Global Numerical Optimization, IEEE Trans. Evol. Comput., 13, 398–417, 2009.
Reeves, C. R. (Ed.): Modern Heuristic Techniques for Combinatorial Problems, John Wiley & Sons, Inc., New York, NY, USA, 320 pp., 1993.
Ridgeway, G.: Generalized Boosted Models: A guide to the gbm package, 1–15, https://doi.org/10.1111/j.1467-9752.1996.tb00390.x, 2012.
Ridgeway, G.: R package “gbm”: Generalized Boosted Regression Models, available at: https://cran.r-project.org/web/packages/gbm/index.html last access: 5 July 2019), 2017.
Rocha Campos, J. R. da, Silva, A. C., Fernandes, J. S. C., Ferreira, M. M., and Silva, D. V.: Water retention in a peatland with organic matter in different decomposition stages, Rev. Bras. Ciência do Solo, 35, 1217–1227, https://doi.org/10.1590/s0100-06832011000400015, 2011.
Sagar, R., Raghubanshi, A. S., and Singh, J. S.: Tree species composition, dispersion and diversity along a disturbance gradient in a dry tropical forest region of India, For. Ecol. Manage., 186, 61–71, https://doi.org/10.1016/S0378-1127(03)00235-4, 2003.
Schmidt, M., Safarani, S., Gastinger, J., Jacobs, T., Nicolas, S., and Schulke, A.: On the Performance of Differential Evolution for Hyperparameter Tuning, in: International Joint Conference on Neural Networks (IJCNN), 1–8, 2019.
Schwärzel, K., Renger, M., Sauerbrey, R., and Wessolek, G.: Soil physical characteristics of peat soils, J. Plant Nutr. Soil Sci., 165, 479–486, 2002.
Schwärzel, K., Šimůnek, J., Stoffregen, H., Wessolek, G., and van Genuchten, M. T.: Estimation of the Unsaturated Hydraulic Conductivity of Peat Soils: Laboratory versus Field Data, Vadose Zo. J., 5, 628, https://doi.org/10.2136/vzj2005.0061, 2006.
Shang, S.: Log-Cubic Method for Generation of Soil Particle Size Distribution Curve, Sci. World J., 1–7, https://doi.org/10.1155/2013/579460, 2013.
Shein, E. V. and Arkhangel'skaya, T. A.: Pedotransfer functions: State of the art, problems, and outlooks, Eurasian Soil Sci., 39, 1089–1099, https://doi.org/10.1134/S1064229306100073, 2006.
Singh, M. K., Astley, H., Smith, P., and Ghoshal, N.: Soil CO2-C flux and carbon storage in the dry tropics: Impact of land-use change involving bioenergy crop plantation, Biomass Bioener., 83, 123–130, https://doi.org/10.1016/j.biombioe.2015.09.009, 2015.
Slowik, A. and Bialko, M.: Training of artificial neural networks using differential evolution algorithm, in: Conference on Human System Interactions, Krakow, 60–65, 2008.
Storn, R. and Price, K.: Differential evolution – A simple and efficient adaptive scheme for global optimization over continuous spaces, 12 pp., 1995.
Tien Bui, D., Nguyen, Q. P., Hoang, N. D., and Klempe, H.: A novel fuzzy K-nearest neighbor inference model with differential evolution for spatial prediction of rainfall-induced shallow landslides in a tropical hilly area using GIS, Landslides, 14, 1–17, https://doi.org/10.1007/s10346-016-0708-4, 2017.
Tóth, B., Weynants, M., Nemes, A., Makó, A., Bilas, G., and Tóth, G.: New generation of hydraulic pedotransfer functions for Europe, Eur. J. Soil Sci., 66, 226–238, https://doi.org/10.1111/ejss.12192, 2015.
Twarakavi, N. K. C., Šimůnek, J., and Schaap, M. G.: Development of Pedotransfer Functions for Estimation of Soil Hydraulic Parameters using Support Vector Machines, Soil Sci. Soc. Am. J., 73, 1443, https://doi.org/10.2136/sssaj2008.0021, 2009.
Van Looy, K., Bouma, J., Herbst, M., Koestel, J., Minasny, B., Mishra, U., Montzka, C., Nemes, A., Pachepsky, Y. A., Padarian, J., Schaap, M. G., Tóth, B., Verhoef, A., Vanderborght, J., van der Ploeg, M. J., Weihermüller, L., Zacharias, S., Zhang, Y., and Vereecken, H.: Pedotransfer Functions in Earth System Science: Challenges and Perspectives, Rev. Geophys., 55, 1199–1256, https://doi.org/10.1002/2017RG000581, 2017.
Vasques, G. M., Coelho, M. R., Dart, R. O., Oliveira, R. P., and Teixeira, W. G.: Mapping soil carbon, particle-size fractions, and water retention in tropical dry forest in Brazil, Pesqui. Agropecu. Bras., 51, 1371–1385, https://doi.org/10.1590/S0100-204X2016000900036, 2016.
Vereecken, H., Javaux, M., Weynants, M., Pachepsky, Y., Schaap, M. G., and Genuchten, V.: Using pedotransfer functions to estimate the van genuchten-mualem soil hydraulic properties: A review, Vadose Zo. J., 9, 795–820, https://doi.org/10.2136/vzj2010.0045, 2010.
Viscarra Rossel, R. A., Behrens, T., Ben-Dor, E., Brown, D. J., Demattê, J. A. M., Shepherd, K. D., Shi, Z., Stenberg, B., Stevens, A., Adamchuk, V., Aïchi, H., Barthès, B. G., Bartholomeus, H. M., Bayer, A. D., Bernoux, M., Böttcher, K., Brodský, L., Du, C. W., Chappell, A., Fouad, Y., Genot, V., Gomez, C., Grunwald, S., Gubler, A., Guerrero, C., Hedley, C. B., Knadel, M., Morrás, H. J. M., Nocita, M., Ramirez-Lopez, L., Roudier, P., Campos, E. M. R., Sanborn, P., Sellitto, V. M., Sudduth, K. A., Rawlins, B. G., Walter, C., Winowiecki, L. A., Hong, S. Y., and Ji, W.: A global spectral library to characterize the world's soil, Earth-Sci. Rev., 155, 198–230, https://doi.org/10.1016/j.earscirev.2016.01.012, 2016.
Wadoux, A. M.-C., Brus, D. J., and Heuvelink, G. B. M.: Accounting for non-stationary variance in geostatistical mapping of soil properties, Geoderma, 324, 138–147, https://doi.org/10.1016/j.geoderma.2018.03.010, 2018.
Wang, S., Zhuang, Q., Wang, Q., Jin, X., and Han, C.: Mapping stocks of soil organic carbon and soil total nitrogen in Liaoning Province of China, Geoderma, 305, 250–263, https://doi.org/10.1016/j.geoderma.2017.05.048, 2017.
Weiss, R., Alm, J., Laiho, R., and Laine, J.: Modeling moisture retention in peat soils, Soil Sci. Soc. Am. J., 62, 305–313, https://doi.org/10.2136/sssaj1998.03615995006200020002x, 1998.
Witten, I. H., Frank, E., and Hall, M. A.: Data Mining Practical Machine Learning Tools and Techniques, 3 Edn., Morgan Kaufmann, 629 pp., 2011.
Wolpert, D. H.: The Supervised Learning No-Free-Lunch Theorems, in 6th Online World Conference on Soft Computing in Industrial Applications, 25–42, 2001.
Wu, J., Teng, Y., Chen, H., and Li, J.: Machine-learning models for on-site estimation of background concentrations of arsenic in soils using soil formation factors, J. Soils Sediments, 16, 1787–1797, https://doi.org/10.1007/s11368-016-1374-9, 2016.
Yang, R. M., Zhang, G. L., Liu, F., Lu, Y. Y., Yang, F., Yang, F., Yang, M., Zhao, Y. G., and Li, D. C.: Comparison of boosted regression tree and random forest models for mapping topsoil organic carbon concentration in an alpine ecosystem, Ecol. Indic., 60, 870–878, https://doi.org/10.1016/j.ecolind.2015.08.036, 2016.
Yang, Y. H., Xu, X. Bin, He, S. B., Wang, J. B., and Wen, Y. H.: Cluster-based niching differential evolution algorithm for optimizing the stable structures of metallic clusters, Comput. Mater. Sci., 149, 416–423, https://doi.org/10.1016/j.commatsci.2018.03.055, 2018.
Yin, Z. Y., Jin, Y. F., Shen, J. S., and Hicher, P. Y.: Optimization techniques for identifying soil parameters in geotechnical engineering: Comparative study and enhancement, Int. J. Numer. Anal. Methods Geomech., 42, 70–94, https://doi.org/10.1002/nag.2714, 2018.